ChatGPTが世間で話題になってから、早いもので約半年経過しました。
そんな中で、改めて大規模言語モデル(LLM)で注目を浴びた生成系AIがどういった物であるのか、できる事、できない事などについてを業務で生成系AIを用いたシステムを開発している立場として学んだ内容をかみ砕いで皆さんと共有できればと思い、記事を書きます。
今回は、主にOpenAI社が開発したGPTモデルに焦点を当てての記載になります。
Googleの開発したTransformerなどの基礎技術については触れません。
対象読者
- これから生成系AIを学ぶ人
- なんとなく知っているけれど、改めて客観視したい人
逆に、生成系AIへの理解は完璧!!と言う人には物足りない内容になってしまいます。
目次
- 大規模言語モデルとは
- 生成系AIが得意な事、苦手な事
- 生成AIを便利に使いこなすための捉え方
大規模言語モデルとは
大規模言語モデル(だいきぼげんごモデル、英: large language model、LLM)は、多数のパラメータ(数千万から数十億)を持つ人工ニューラルネットワークで構成されるコンピュータ言語モデルで、膨大なラベルなしテキストを使用して自己教師あり学習または半教師あり学習(英語版)によって訓練が行われる[1]。
大規模言語モデル – Wikipedia
膨大なテキストデータを用いて、機械学習された学習データの総称です。
今話題のOpenAIが開発したGPTでは1750億ものパラメータが利用されていると言われています。
パラメータが多ければ優秀なのかと言うと、必ずしもYESとは言えないのが現状です。精度が向上することは確かではあるのですが、優秀かどうかは別の軸も関わってきます。
GPTが優れている理由は、学習後のチューニングが人間が求める答えを出しやすいように微調整されているからです。
GPTモデルでは、学習データを元に確率が高いものを選択して、それっぽい答えを推論して生成しています。
有名な”吾輩は猫である”は確率的が高いですが、一方で学習データ的には”吾輩は猫になりたい”と推論される可能性は低いです。
その為、人類がみな猫になりたいという願望を持っていようとも、通常では夏目漱石の有名な一文が返答される結果となります。
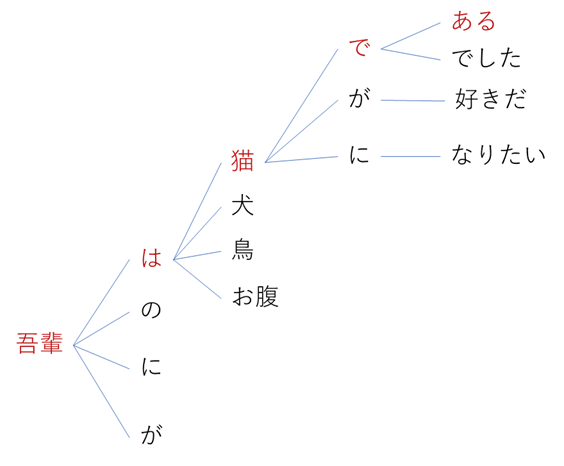
重要なのは、考える力そのものを持っているわけではなく、事前に学習したデータを基準に、推論しているにすぎないと言う事です。
ただし、その推論の精度が非常に高いため、汎用的なジェネレータとして優秀な結果を残していると言う事になります。
あらゆる分野で大学3年生並みと言うのは素晴らしい汎用的な知識ですよね。
生成系AI(GPT)が得意な事、苦手な事
得意な事としては、文章の生成や補完,要約のほか、質問への応答や対話システムなどの自然言語処理タスクです。
苦手な事としては、総合的に判断が必要になることに対してはそれっぽい事は返答しますが、いわゆるハルシネーション(Hallucination)と言う現象を起こしやすくなります。あまりにもそれっぽいので、騙されてしまいます。
また、計算なども苦手な分野となっています。計算については、ステップバイステップでと言う指示を行う事で、精度を向上させることが出来るとの事ですが、コンピュータとしては信頼度が低いです。
生成AIを便利に使いこなすために
Chat GPT の構造を、俯瞰して整理することで、生成AIを用いて何か便利な事をしたい、便利なツールを開発したい。と言う要望に応えやすくなると思います。
結論だけ先に書くと、生成AIを使ってみたいという好奇心を抑え、本当に生成AIを使うべきなのか?
問題+解決方法=うれしい未来の構図を実現するために行うべきなのは、問題を正しく理解して、仕組みを変更するなどの解決方法が正しい場合も有ります。
生成AIは膨大な一般的なデータを学習して、確率と言うルールを基本として出力を生成するという動きをしています。
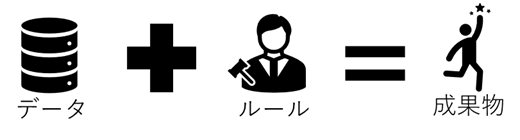
このように抽象化して分解してみた場合、使いこなすにはデータとルールをどのように定義するのかorどちらかを定義しないでLLMが基本として持っている範囲内で活用することが重要になってきます。
例えば、社内データを活用するとなると一般的なデータには存在しないことから、追加のデータとして覚えさせてあげる必要が有ります。
いわゆる、Retrieval Augmented Generationという社内データの検索+検索結果をデータとして与えるという作業を行う必要が有ります。
ただし、ルールとしてはLLMの基本的な推論+少しの返答ルールやキャラ付けを行えば実現可能です。
そのほかに、文章の査読をさせたいというユースケースを考えてみます。
その場合、一般的なメールや設計書の場合、データは独自性が不要であると言えます。また、ルールについても、校閲の観点は端的な指示として言語化されているので、システムメッセージとして事前低コストで指示可能です。
逆に、社内の申請についてのチェックをさせたいというユースケースを考えてみます。
その場合、社内申請としての独自用語含めたデータの用意が必要になる場合が有ります。
一番大変なのがルールの選定です。社内申請の合否や指摘事項などになると、汎用的なルールは利用できませんし、更には合否条件の事細かなルールをLLMが理解できるように簡潔に定義する作業。指摘として発生する内容。それらを漏れなく定義する必要が出てきます。
その事から、社内申請関連のチェックには適していないと言えます。
一部では、データ分析に活用できるとの見方も有りますがFew-shotとして分析ルールを如何にして与えられるかと言うところがカギとなっていきます。
それゆえに、得意と言う見方も有りますが、苦手と言う見方もできると思います。
あくまでも、汎用性の高いジェネレータであるという認識。
また、その汎用性を作り出しているデータ+ルールに沿った生成と言う事を忘れない事が重要だと考えています。
何でもできる、神の作り出したツールではないという認識を持たないと、絶望してしまいます。
最後に
生成AIは比較的新しい技術分野であることと、爆発的に流行ったものであり、更にいまだ日々進歩している分野となっています。
その為、なんでもできるスーパーAIと認識している人もいれば、現実的に考えてアレに活用できるな~と言う認識をしている人との差が激しいと感じています。
この記事で書いた内容が少しでも正しい認知を行うための考え方の助けになればうれしいです。
今後も、情報に変化が有った場合は適宜、加筆更新して行ければと考えています。